
The software stack that manages CloudLab is based on Emulab, a testbed control suite that has been developed by the Flux Research Group at the University of Utah. Emulab’s primary strength lies in provisioning an ensemble of resources at the physical level, giving experimenters “raw” access to compute, network, and storage resources. The description of an ensemble includes a full description of the network, enabling Emulab to tightly control network topologies and to do network-aware resource placement. It places the infrastructure layer below the cloud software architecture, enabling experimenters to run cloud software stacks such as OpenStack, Eucalyptus, and CloudStack as experiments within CloudLab. Some of these experiments may be very long-lived, representing persistent production-quality clouds that may themselves offer cloud services to other users for years at a time. Others may last weeks, days, or even hours, representing targeted experiments to test specific hypotheses. CloudLab is extremely flexible in its allocation policies, as the Emulab software is capable of fast re-provisioning, switching between experiments (in this case, entire clouds) on the order of minutes.
The technology behind Emulab was first described in a paper at OSDI, and dozens of subsequent papers have covered further steps in its evolution.


GENI is a distributed infrastructure built by the National Science Foundation to support research in networks and distributed systems. CloudLab uses many technologies that were originally developed for GENI.
GENI is built around federation: this allows each one of the clusters that comprise CloudLab to operate autonomously, but to be seamlessly combined into a single whole for running large experiments. It also means that any testbed that supports the GENI APIs may federate with CloudLab.
GENI has a rich API for listing, requesting, and controlling resources, as well as full language for describing resources. CloudLab offers a straightforward web-based GUI for building clouds, but the full power of GENI is available through these APIs. Many tools that work with GENI will also work out of the box on CloudLab.
CloudLab uses profiles to describe the hardware and software needed to build a cloud. A profile can be as simple as a “clean slate” installation of a standard operating system on bare metal hosts, or it can contain an entire software stack. The profile shown below contains a canned instance of OpenStack.
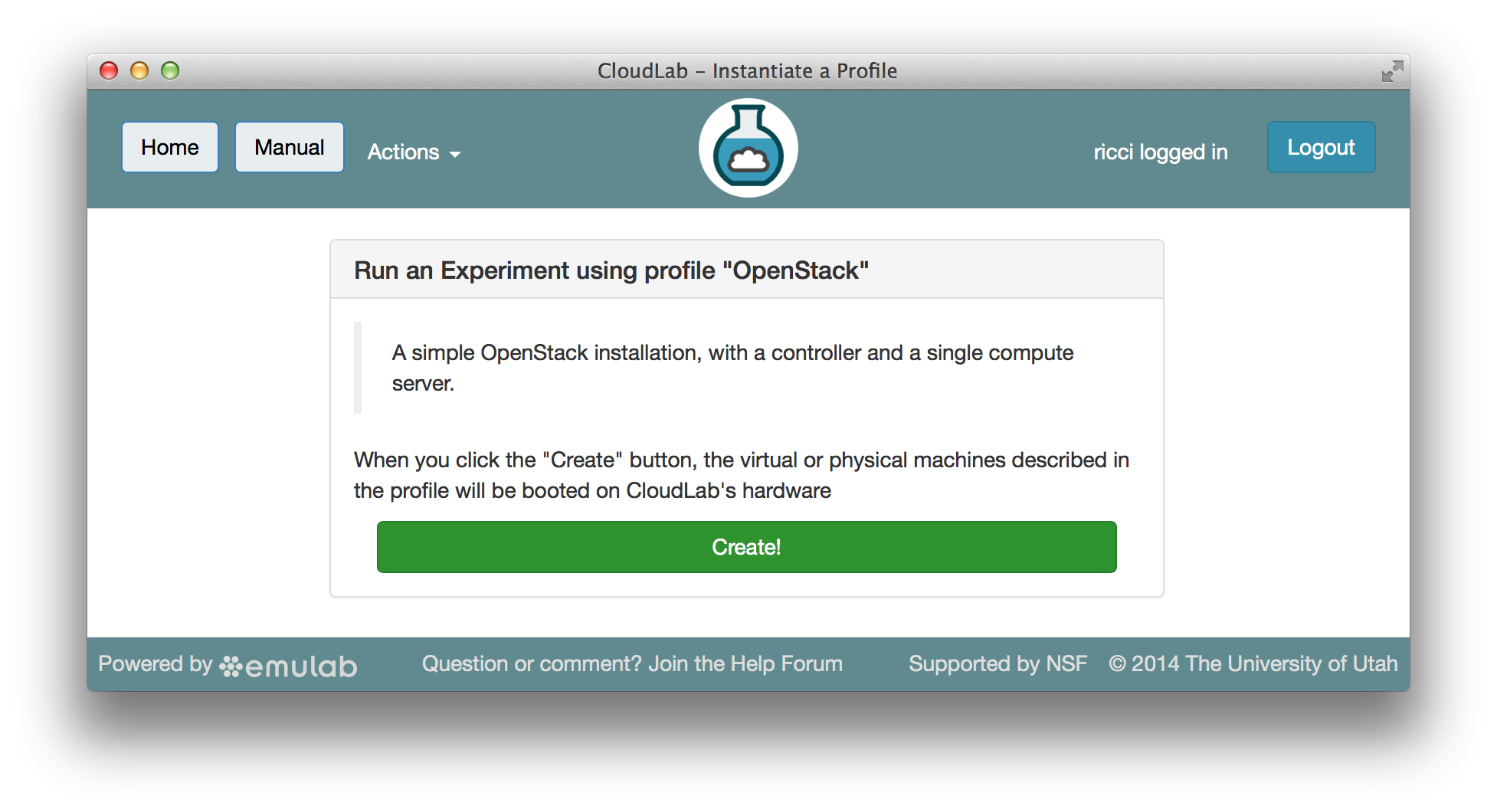
The create button causes CloudLab to start provisioning the hardware resources specified by the profile and loading the appropriate software on them. When all provisioning is done (which typically takes a few minutes), you get a screen like the one below, showing the resources that have been allocated to your cloud. The resources allocated to you are for your exclusive use for the duration of the experiment (though you can open up the cloud to other users if you choose.)
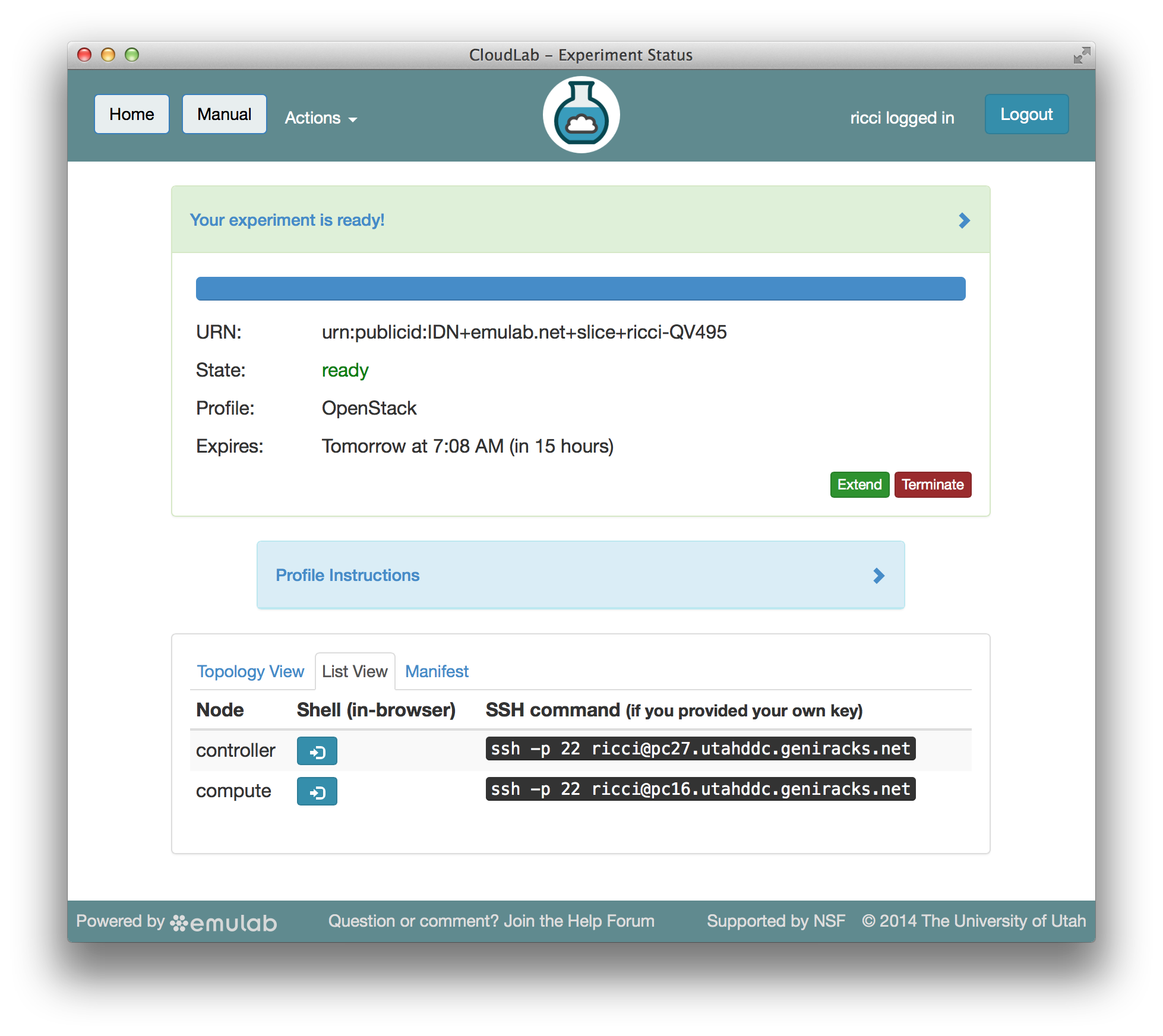
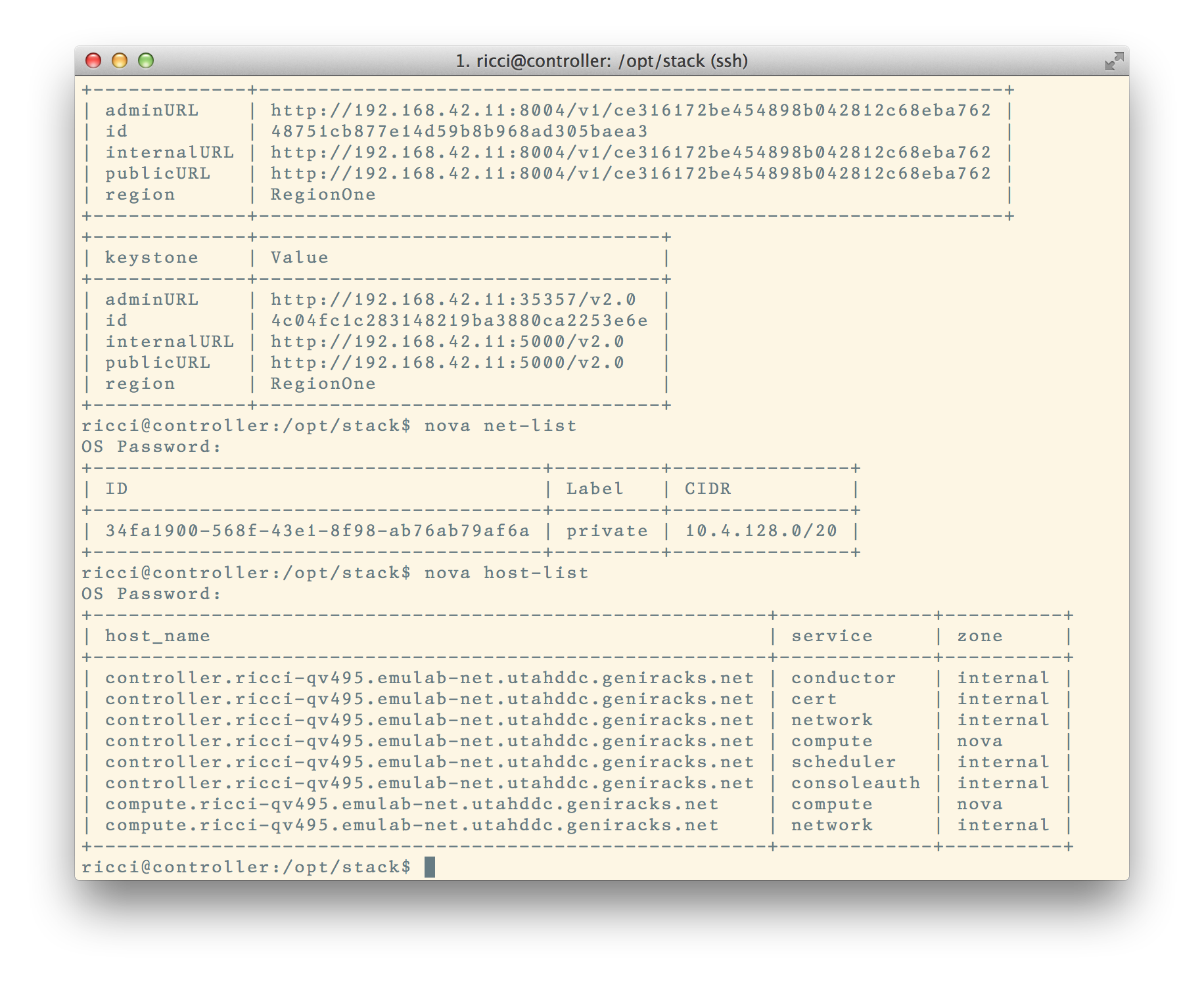
Once your cloud is ready, you can interact with it directly. The pictures below show an instance of OpenStack that's running inside of CloudLab. You have full control over all of the machines, including the controller, and can replace any piece of software you want!

To provide bare-metal access, CloudLab PXE-boots all physical nodes and use a custom boot loader to control the first-stage boot process: this allows it to get control back between users. Our boot loader can handle booting local disk or booting network-loaded kernels. One of the uses for the latter is imaging local disks: we built a custom, extremely fast, highly-scalable multicast disk loader to accomplish this. Taken together, this lets CloudLab re-provision machines at a bare-metal level rapidly (actual disk loads often take less than a minute) and give users nearly full control. CloudLab will have the ability to power cycle or perform hard resets on all nodes to recover them if they become wedged. We take the security of the re-imaging process seriously—we have built a TPM-based secure disk loading system. We also use a sophisticated state machine system that tracks the boot process of the nodes at multiple stages. It takes action to recover from a variety of failure modes, and in some cases, will even give up on one machine and re-provision another to take its place.